机器学习代写|监督学习代考Supervised and Unsupervised learning代写|Feature Reduction with Support Vector
如果你也在 怎样代写监督学习Supervised and Unsupervised learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
监督学习算法从标记的训练数据中学习,帮你预测不可预见的数据的结果。成功地建立、扩展和部署准确的监督机器学习数据科学模型需要时间和高技能数据科学家团队的技术专长。此外,数据科学家必须重建模型,以确保给出的见解保持真实,直到其数据发生变化。
statistics-lab™ 为您的留学生涯保驾护航 在代写监督学习Supervised and Unsupervised learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写监督学习Supervised and Unsupervised learning代写方面经验极为丰富,各种代写监督学习Supervised and Unsupervised learning相关的作业也就用不着说。
我们提供的监督学习Supervised and Unsupervised learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
机器学习代写|监督学习代考Supervised and Unsupervised learning代写|Machines and Application
Since this chapter is mainly related to feature reduction using SVMs in DNA microarray analysis, it is essential to understand the basic steps involved in a microarray experiment and why this technology has become a major tool for biologists to investigate the function of genes and their relations to a particular disease.
In an organism, proteins are responsible for carrying out many different functions in the life-cycle of the organism. They are the essential part of many biological processes. Each protein consists of chain of amino acids in a specific order and it has unique functions. The order of amino acids is determined by the DNA sequences in the gene which codes for a specific proteins. To produce a specific protein in a cell, the gene is transcribed from DNA into a messenger RNA (mRNA) first, then the mRNA is converted to a protein via translation.
To understand any biological process from a molecular biology perspective, it is essential to know the proteins involved. Currently, unfortunately, it is very difficult to measure the protein level directly because there are simply too many of them in a cell. Therefore, the levels of mRNA are used as a surrogate measure of how much a specific protein is presented in a sample, i.e. it gives an indication of the levels of gene expression. The idea of measuring the level of mRNA as a surrogate measure of the level of gene expression dates back to $1970 \mathrm{~s}[21,99]$, but the methods developed at the time allowed only a few genes to be studied at a time. Microarrays are a recent technology which allows mRNA levels to be measured in thousands of genes in a single experiment.
The microarray is typically a small glass slide or silicon wafer, upon which genes or gene fragment are deposited or synthesized in a high-density manner. To measure thousands of gene expressions in a sample, the first stage in making of a microarray for such an experiment is to determine the genetic materials to be deposited or synthesized on the array. This is the so-called probe selection stage, because the genetic materials deposited on the array are going to serve as probes to detect the level of expressions for various genes in the sample. For a given gene, the probe is generally made up from only part of the DNA sequence of the gene that is unique, i.e. each gene is represented by a single probe. Once the probes are selected, each type of probe will be deposited or synthesized on a predetermined position or “spot” on the array. Each spot will have thousands of probes of the same type, so the level of intensity pick up at each spot can be traced back to the corresponding probe. It is important to note that a probe is normally single stranded (denatured) DNA, so the genetic material from the sample can bind with the probe.
机器学习代写|监督学习代考Supervised and Unsupervised learning代写|Some Prior Work
As mentioned in Chap. 2, maximization of a margin has been proven to perform very well in many real world applications and makes SVMs one of the most popular machine learning algorithms at the moment. Since the margin is the criterion for developing one of the best-known classifiers, it is natural to consider using it as a measure of relevancy of genes or features. This idea of using margin for gene selection was first proposed in [61]. It was achieved by coupling recursive features elimination with linear SVMs (RFE-SVMs) in order to find a subset of genes that maximizes the performance of the classifiers. In a linear SVM, the decision function is given as $f(x)=\mathbf{w}^{T} \mathbf{x}+b$ or $f(x)=\sum_{k=1}^{n} w_{k} x_{k}+b$. For a given feature $x_{k}$, the size of the absolute value of its weight $w_{k}$ shows how significantly does $x_{k}$ contributes to the margin of the linear SVMs and to the output of a linear classifier. Hence, $w_{k}$ is used as a feature ranking coefficient in RFE-SVMs. In the original RFE-SVMs, the algorithm first starts constructing a linear SVMs classifier from the microarray data with $n$ number of genes. Then the gene with the smallest $w_{k}^{2}$ is removed and another classifier is trained on the remaining $n-1$ genes. This process is repeated until there is only one gene left. A gene ranking is produced at the end from the order of each gene being removed. The most relevant gene will be the one that is left at the end. However, for computational reasons, the algorithm is often implemented in such a way that several features are reduced at the same time. In such a case, the method produces a feature subset ranking, as opposed to a feature ranking. Therefore, each feature in a subset may not be very relevant individually, and it is the feature subset that is to some extent optimal [61]. The linear RFE-SVMs algorithm is presented in Algorithm $4.1$ and the presentation here follows closely to [61]. Note that in order to simplify the presentation of the Algorithm $4.1$, the standard syntax for manipulating matrices in MATLAB is used.
机器学习代写|监督学习代考Supervised and Unsupervised learning代写|Influence of the Penalty Parameter C in RFE-SVMs
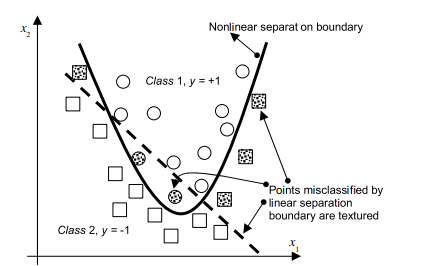
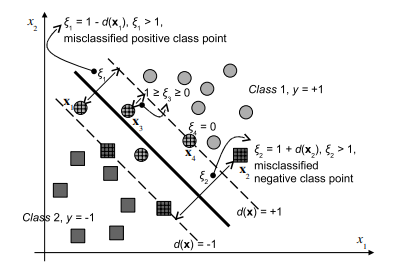
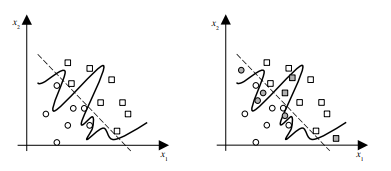
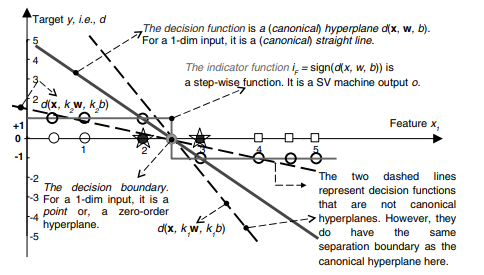
As discussed previously, the formulation presented in (2.10) is often referred to as the “hard” margin SVMs, because the solution will not allow any point to be inside, or on the wrong side of the margin and it will not work when classes are overlapped and noisy. This shortcoming led to the introduction of the slack variables $\xi$ and the $C$ parameter to (2.10a) for relaxing the margin by making it ‘soft’ to obtain the formulation in (2.24). In the soft margin SVMs, $C$ parameter is used to enforce the constraints (2.24b). If $C$ is infinitely large, or larger than the biggest $\alpha_{i}$ calculated, the margin is basically ‘hard’. If $C$ is smaller than the biggest original $\alpha_{i}$, the margin is ‘soft’. As seen from $(2.27 \mathrm{~b})$ all the $\alpha_{j}>C$ will be constrained to $\alpha_{j}=C$ and corresponding data points will be inside, or on the wrong side of, the margin. In most of the work related to RFE-SVMs e.g., $[61,119]$, the $C$ parameter is set to a number that is sufficiently larger than the maximal $\alpha_{i}$, i.e. a hard margin SVM is implemented within such an RFE-SVMs model. Consequently, it has been reported that the performance of RFE-SVMs is insensitive to the parameter $C$. However, Fig. $4.3[72]$ shows how $C$ may influence the selection of more relevant features in a toy example where the two classes (stars $*$ and pluses +) can be perfectly separated in a feature 2 direction only. In other words, the feature 1 is irrelevant for a perfect classification here.
As shown in Fig. 4.3, although a hard margin SVMs classifier can make perfect separation, the ranking of the features based on $w_{i}$ can be inaccurate.
The $C$ parameter also affects the performance of the SVMs if the classes overlap each other. In the following section, the gene selection based on an application of the RFE-SVMs having various $C$ parameters in the cases of two medicine data sets is presented.
监督学习代写
机器学习代写|监督学习代考Supervised and Unsupervised learning代写|Machines and Application
由于本章主要涉及在 DNA 微阵列分析中使用 SVM 进行特征减少,因此有必要了解微阵列实验中涉及的基本步骤以及为什么这项技术已成为生物学家研究基因功能及其与基因的关系的主要工具。一种特殊的疾病。
在有机体中,蛋白质负责在有机体的生命周期中执行许多不同的功能。它们是许多生物过程的重要组成部分。每种蛋白质都由特定顺序的氨基酸链组成,并具有独特的功能。氨基酸的顺序由编码特定蛋白质的基因中的 DNA 序列决定。为了在细胞中产生特定的蛋白质,首先将基因从 DNA 转录为信使 RNA (mRNA),然后通过翻译将 mRNA 转化为蛋白质。
要从分子生物学的角度理解任何生物过程,必须了解所涉及的蛋白质。目前,不幸的是,直接测量蛋白质水平非常困难,因为细胞中的蛋白质太多了。因此,mRNA 水平被用作样品中存在多少特定蛋白质的替代量度,即它给出了基因表达水平的指示。测量 mRNA 水平作为基因表达水平的替代测量的想法可以追溯到1970 s[21,99],但当时开发的方法一次只允许研究几个基因。微阵列是一项最新技术,它允许在一次实验中测量数千个基因的 mRNA 水平。
微阵列通常是小玻璃载玻片或硅晶片,基因或基因片段以高密度方式沉积或合成在其上。为了测量样本中的数千个基因表达,为此类实验制作微阵列的第一步是确定要在阵列上沉积或合成的遗传物质。这就是所谓的探针选择阶段,因为沉积在阵列上的遗传物质将作为探针来检测样本中各种基因的表达水平。对于给定的基因,探针通常仅由该基因的独特DNA序列的一部分组成,即每个基因由单个探针代表。一旦选择了探针,每种类型的探针将被沉积或合成在阵列上的预定位置或“点”上。每个点将有数千个相同类型的探针,因此每个点的强度水平可以追溯到相应的探针。需要注意的是,探针通常是单链(变性)DNA,因此样本中的遗传物质可以与探针结合。
机器学习代写|监督学习代考Supervised and Unsupervised learning代写|Some Prior Work
如第 1 章所述。2、最大化边际已被证明在许多现实世界的应用中表现得非常好,并使支持向量机成为目前最流行的机器学习算法之一。由于边距是开发最著名的分类器之一的标准,因此很自然地考虑将其用作基因或特征相关性的度量。这种使用边缘进行基因选择的想法最早是在[61]中提出的。它是通过将递归特征消除与线性 SVM (RFE-SVM) 相结合来实现的,以便找到最大化分类器性能的基因子集。在线性 SVM 中,决策函数为F(X)=在吨X+b或者F(X)=∑ķ=1n在ķXķ+b. 对于给定的特征Xķ,其权重绝对值的大小在ķ显示了多么显着Xķ有助于线性 SVM 的边缘和线性分类器的输出。因此,在ķ用作 RFE-SVM 中的特征排序系数。在最初的 RFE-SVMs 中,该算法首先开始从微阵列数据构建线性 SVMs 分类器n基因数量。那么最小的基因在ķ2被移除,另一个分类器在剩余的n−1基因。重复这个过程,直到只剩下一个基因。最后根据每个基因被删除的顺序产生一个基因排名。最相关的基因将是最后留下的基因。然而,出于计算原因,该算法通常以同时减少几个特征的方式实现。在这种情况下,该方法生成特征子集排名,而不是特征排名。因此,子集中的每个特征可能不是非常相关,并且在某种程度上是最优的特征子集[61]。算法中介绍了线性 RFE-SVMs 算法4.1这里的介绍紧跟[61]。请注意,为了简化算法的表示4.1,使用在 MATLAB 中操作矩阵的标准语法。
机器学习代写|监督学习代考Supervised and Unsupervised learning代写|Influence of the Penalty Parameter C in RFE-SVMs
如前所述,(2.10) 中提出的公式通常被称为“硬”边距 SVM,因为该解决方案不允许任何点位于边距内或边距的错误一侧,并且在分类时不起作用重叠和嘈杂。这个缺点导致引入松弛变量X和C(2.10a)的参数通过使其“软”来放松裕度以获得(2.24)中的公式。在软边缘 SVM 中,C参数用于强制执行约束 (2.24b)。如果C无限大,或大于最大的一种一世算下来,保证金基本上是“硬”的。如果C小于最大的原件一种一世,边距是“软”的。从(2.27 b)一切一种j>C将被限制在一种j=C并且相应的数据点将在边距内或边距的错误一侧。在大多数与 RFE-SVM 相关的工作中,例如,[61,119], 这C参数设置为比最大值足够大的数字一种一世,即在这样的 RFE-SVM 模型中实现硬边距 SVM。因此,据报道 RFE-SVM 的性能对参数不敏感C. 然而,图。4.3[72]显示如何C可能会影响玩具示例中更多相关特征的选择,其中两个类(星∗加号 +) 只能在特征 2 方向上完美分离。换句话说,特征 1 与这里的完美分类无关。
如图 4.3 所示,虽然硬边距 SVM 分类器可以进行完美的分离,但基于特征的排序在一世可能不准确。
这C如果类相互重叠,参数也会影响 SVM 的性能。在下一节中,基于 RFE-SVM 应用的基因选择具有各种C给出了两个医学数据集的情况下的参数。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。