如果你也在 怎样代写机器学习Machine Learning这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
机器学习是人工智能(AI)和计算机科学的一个分支,主要是利用数据和算法来模仿人类的学习方式,逐步提高其准确性。
机器学习是不断增长的数据科学领域的一个重要组成部分。通过使用统计方法,算法被训练来进行分类或预测,在数据挖掘项目中发现关键的洞察力。这些洞察力随后推动了应用程序和业务的决策,最好是影响关键的增长指标。随着大数据的不断扩大和增长,市场对数据科学家的需求将增加,需要他们协助确定最相关的业务问题,随后提供数据来回答这些问题。
statistics-lab™ 为您的留学生涯保驾护航 在代写机器学习Machine Learning方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写机器学习方面经验极为丰富,各种代写机器学习Machine Learning相关的作业也就用不着说。
我们提供的机器学习Machine Learning及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|机器学习作业代写Machine Learning代考|Financial Risk Management
Though it is theoretically intuitive, the assumption of completely rational decision maker, main building block in modern finance theory, is too perfect to be real. This idea, therefore, attacked by behavioral economists, who believes that psychology plays a key role in decision making process.
Making decisions is like speaking prose – people do it all the time, knowingly or unknowingly. It is hardly surprising, then, that the topic of decision making is shared by many disciplines, from mathematics and statistics, through economics and political science, to sociology and psychology.
-Kahneman and Tversky (1984)
Information asymmetry and financial risk management goes hand in hand as cost of financing and firm valuation are deeply affected by the information asymmetry. That is, uncertainty in valuation of a firm’s assets might raise the borrowing cost posing a threat to a firm’s sustainability (See DeMarzo and Darrell (1995) and Froot, Scharfstein, and Stein (1993)).
Thus, roots of the failures described above lie deeper in such a way that perfect hypothetical world in which rational decision maker lives is unable to explain them. At this point, human instincts and imperfect world come into play and a mixture of disciplines provide more plausible justifications. So, it turns out Adverse Selection and Moral Hazard are two prominents categories accounting for the market failures.
统计代写|机器学习作业代写Machine Learning代考|Adverse Selection
It is a type of asymmetric information in which one party tries to exploit its informational advantage. Adverse selection arises when seller are better informed than buyers. This phemomenon is perfectly coined by Akerlof $(1970)$ as “The Markets for Lemons”. Within this framework, lemons refer to low-quality.
Consider a market with lemon and high-quality cars and buyers know that it is likely to buy a lemon, which lowers then equilibrium price. However, seller is better informed if the car is lemon or high-quality. So, in this situation, benefit from exchange might disappear and no transaction takes place.
Due to the complexity and opaqueness, mortgage market in the pre-crisis era is a good example of adverse selection. More elaborately, borrowers knew more about their willingness and ability to pay than lenders. Financial risk was created through the securitizations of the loans, i.e., mortgage backed securities. From this point on, the originators of the mortgage loans knew more about the risks than the people they were selling them to investors in the mortgage backed securities.
Let us try to model adverse selection using Python. It is readily observable in insurance industry and therefore I would like to focus on this industry to model adverse selection.
Supposc that the consumer utility function is:
$$
U(x)=e^{\gamma x}
$$
where $\mathrm{x}$ is income and $\gamma$ is a parameter, which takes on values between 0 and $1 .$
The ultimate aim of this example is to decide whether or not to buy an insurance based on consumer utility.
For the sake of practice, I assume that the income is $\$ 2 \mathrm{USD}$ and cost of the accident is \$1.5 USD.
Now it is time to calculate the probability of loss, $\pi$, which is exogenously given and it is uniformly distributed.
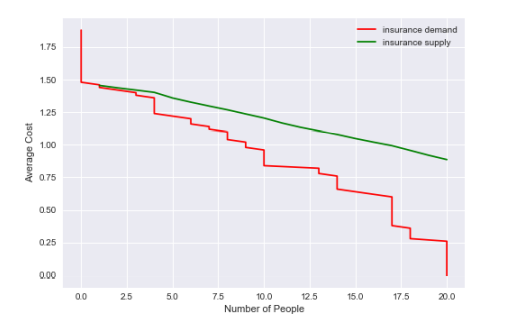
As a last step, in order to find equilibrium, I have to define supply and demand for insurance coverage. The following code block indicates how we can model the adverse selection.
统计代写|机器学习作业代写Machine Learning代考|Moral Hazard
Market failures also result from asymmetric information. In moral hazard situation, one party of the contract assumes more risk than the other party. Formally, moral hazard may be defined as a situation in which more informed party takes advantages of the private information at his disposal to the detriment of others.
For a better understanding of moral hazard, a simple example can be given from the credit market: Suppose that entity A demands credit for use in financing the project, which is considered as feasible to finance. Moral hazurd arises if entity A utilizes the loan for the payment of oredit debt to bank $\mathrm{C}$, without prior notice to the lender bank. While allocating credit, the moral hazard situation that banks may encounter arises as a result of asymmetric information, decreases banks’ lending appetites and appears as one of the reasons why banks put so much labor on credit allocation process.
Some argue that rescue operation undertaken by FED for LCTM can be considered as moral hazard in a way that FED enters into contracts on bad faith.
机器学习代写
统计代写|机器学习作业代写Machine Learning代考|Financial Risk Management
尽管在理论上是直观的,但完全理性决策者的假设,现代金融理论的主要组成部分,过于完美而无法实现。因此,这一想法受到行为经济学家的攻击,他们认为心理学在决策过程中起着关键作用。
做决定就像说散文——人们一直在做,有意或无意。因此,从数学和统计学到经济学和政治学,再到社会学和心理学,许多学科都共享决策这一主题也就不足为奇了。
——卡尼曼和特沃斯基(1984)
信息不对称与财务风险管理齐头并进,因为信息不对称对融资成本和公司估值的影响很大。也就是说,公司资产估值的不确定性可能会提高借贷成本,从而对公司的可持续性构成威胁(参见 DeMarzo 和 Darrell (1995) 以及 Froot、Scharfstein 和 Stein (1993))。
因此,上述失败的根源更深,以至于理性决策者生活的完美假设世界无法解释它们。在这一点上,人类的本能和不完美的世界开始发挥作用,学科的混合提供了更合理的理由。因此,事实证明逆向选择和道德风险是导致市场失灵的两个突出类别。
统计代写|机器学习作业代写Machine Learning代考|Adverse Selection
它是一种不对称信息,其中一方试图利用其信息优势。当卖方比买方更了解情况时,就会出现逆向选择。这种现象完全由阿克洛夫创造(1970)作为“柠檬市场”。在这个框架内,柠檬指的是低质量的。
考虑一个有柠檬和高质量汽车的市场,买家知道它可能会购买柠檬,这会降低均衡价格。但是,如果汽车是柠檬车还是优质车,卖家会更好地了解情况。因此,在这种情况下,从交换中获得的收益可能会消失,并且不会发生交易。
由于复杂性和不透明性,危机前时代的抵押贷款市场是逆向选择的一个很好的例子。更详细地说,借款人比贷款人更了解他们的支付意愿和能力。金融风险是通过贷款证券化(即抵押支持证券)产生的。从那时起,抵押贷款的发起人比他们向抵押贷款支持证券的投资者出售贷款的人更了解风险。
让我们尝试使用 Python 对逆向选择进行建模。它在保险行业很容易观察到,因此我想专注于这个行业来模拟逆向选择。
假设消费者效用函数为:
ü(X)=和CX
在哪里X是收入和C是一个参数,取值介于 0 和1.
这个例子的最终目的是根据消费者效用决定是否购买保险。
为了实践起见,我假设收入是$2ü小号D事故费用为1.5 美元。
现在是计算损失概率的时候了,圆周率,它是外生给定的,并且是均匀分布的。
作为最后一步,为了找到平衡,我必须定义保险范围的供需。以下代码块指示我们如何对逆向选择进行建模。
统计代写|机器学习作业代写Machine Learning代考|Moral Hazard
市场失灵也源于信息不对称。在道德风险情况下,合同一方承担的风险大于另一方。形式上,道德风险可以定义为更知情的一方利用他掌握的私人信息损害他人的情况。
为了更好地理解道德风险,可以从信贷市场举一个简单的例子:假设实体 A 需要信贷来为项目融资,这被认为是可行的。如果实体 A 将贷款用于向银行支付或编辑债务,则会出现道德风险C,无需事先通知贷方银行。在信贷配置过程中,由于信息不对称,银行可能遇到的道德风险情况,降低了银行的放贷意愿,成为银行在信贷配置过程中投入大量精力的原因之一。
一些人认为,美联储为 LCTM 采取的救援行动可以被视为道德风险,因为美联储在签订合同时是出于恶意。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。统计代写|python代写代考
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。