统计代写|生物统计代写biostatistics代考|MPH701
如果你也在 怎样代写生物统计biostatistics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
生物统计学是将统计技术应用于健康相关领域的科学研究,包括医学、生物学和公共卫生,并开发新的工具来研究这些领域。
statistics-lab™ 为您的留学生涯保驾护航 在代写生物统计biostatistics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写生物统计biostatistics代写方面经验极为丰富,各种生物统计biostatistics相关的作业也就用不着说。
我们提供的生物统计biostatistics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等概率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
统计代写|生物统计代写biostatistics代考|Extension to the Regression Case
We want to extend the methodology of Sect. $3.2$ to the regression setting where the location parameter varies across observations as a linear function of a set of $p$, say, explanatory variables, which are assumed to include the constant term, as it is commonly the case. If $x_{i}$ is the vector of covariates pertaining to the $i$ th subject, observation $y_{i}$ is now assumed to be drawn from ST $\left(\xi_{i}, \omega, \lambda, \nu\right)$ where
$$
\xi_{i}=x_{i}^{\top} \beta, \quad i=1, \ldots, n,
$$
for some $p$-dimensional vector $\beta$ of unknown parameters; hence now the parameter vector is $\theta=\left(\beta^{\top}, \omega, \lambda, v\right)^{\top}$. The assumption of independently drawn observations is retained.
The direct extension of the median as an estimate of location, which was used in Sect. 3.2, is an estimate of $\beta$ obtained by median regression, which corresponds to adoption of the least absolute deviations fitting criterion instead of the more familiar least squares. This can also be viewed as a special case of quantile regression, when the quantile level is set at $1 / 2$. A classical treatment of quantile regression
is Koenker (2005) and corresponding numerical work can be carried out using the $R$ package quantreg, see Koenker (2018), among other tools.
Use of median regression delivers an estimate $\tilde{\tilde{\beta}}^{m}$ of $\beta$ and a vector of residual values, $r_{i}=y_{i}-x_{i}^{\top} \tilde{\beta}^{m}$ for $i=1, \ldots, n$. Ignoring $\beta$ estimation errors, these residuals are values sampled from $\mathrm{ST}\left(-m_{0}, \omega^{2}, \lambda, v\right)$, where $m_{0}$ is a suitable value, examined shortly, which makes the distribution to have 0 median, since this is the target of the median regression criterion. We can then use the same procedure of Sect. 3.2, with the $y_{i}$ ‘s replaced the $r_{i}$ ‘s, to estimate $\omega, \lambda, v$, given that the value of $m_{0}$ is irrelevant at this stage.
The final step is a correction to the vector $\tilde{\beta}^{m}$ to adjust for the fact that $y_{i}-x_{i}^{\top} \beta$ should have median $m_{0}$, that is, the median of ST $(0, \omega, \lambda, v)$, not median 0 . This amounts to increase all residuals by a constant value $m_{0}$, and this step is accoomplishéd by sêtting a vectoor $\tilde{\beta}$ with all components equal tō $\tilde{\beta}^{m}$ except that the intercept term, $\beta_{0}$ say, is estimated by
$$
\tilde{\beta}{0}=\tilde{\beta}{0}^{m}-\tilde{\omega} q_{2}^{\mathrm{ST}}
$$
similarly to $(10)$
统计代写|生物统计代写biostatistics代考|Extension to the Multivariate Case
Consider now the case of $n$ independent observations from a multivariate $Y$ variable with density (6), hence $Y \sim \mathrm{ST}{d}(\xi, \Omega, \alpha, v)$. This case can be combined with the regression setting of Sect. 3.3, so that the $d$-dimensional location parameter varies for each observation according to $$ \xi{i}^{\top}=x_{i}^{\top} \beta, \quad i=1, \ldots, n,
$$
where now $\beta=\left(\beta_{\cdot 1}, \ldots, \beta_{\cdot d}\right)$ is a $p \times d$ matrix of parameters. Since we have assumed that the explanatory variables include a constant term, the regression case subsumes the one of identical distribution, when $p=1$. Hence we deal with the regression case directly, where the $i$ th observation is sampled from $Y_{i} \sim$ $\mathrm{ST}{d}\left(\xi{i}, \Omega, \alpha, v\right)$ and $\xi_{i}$ is given by (12), for $i=1, \ldots, n$.
Arrange the observed values in a $n \times d$ matrix $y=\left(y_{i j}\right)$. Application of the procedure presented in Sects. $3.2$ and $3.3$ separately to each column of $y$ delivers estimates of $d$ univariate models. Specifically, from the $j$ th column of $y$, we obtain estimates $\tilde{\theta}{j}$ and corresponding ‘normalized’ residuals $\tilde{z}{i j}$ :
$$
\tilde{\theta}{j}=\left(\tilde{\beta}{\cdot j}^{\top}, \tilde{\omega}{j}, \tilde{\lambda}{j}, \tilde{v}{j}\right)^{\top}, \quad \tilde{z}{i j}=\tilde{\omega}{j}^{-1}\left(y{i j}-x_{i}^{\top} \tilde{\beta}_{\cdot j}\right)
$$
where it must be recalled that the ‘normalization’ operation uses location and scale parameters, but these do not coincide with the mean and the standard deviation of the underlying random variable.
Since the meaning of expression (12) is to define a set of univariate regression modes with a common design matrix, the vectors $\tilde{\beta}{-1}, \ldots, \tilde{\beta}{\cdot d}$ can simply be arranged in a $p \times d$ matrix $\tilde{\beta}$ which represents an estimate of $\beta$.
The set of univariate estimates in (13) provide $d$ estimates for $v$, while only one such a value enters the specification of the multivariate ST distribution. We have adopted the median of $\tilde{v}{1}, \ldots, \tilde{v}{d}$ as the single required estimate, denoted $\tilde{v}$.
The scale quantities $\tilde{\omega}{1}, \ldots, \tilde{\omega}{d}$ estimate the square roots of the diagonal elements of $\Omega$, but off-diagonal elements require a separate estimation step. What is really required to estimate is the scale-free matrix $\bar{\Omega}$. This is the problem examined next.
If $\omega$ is the diagonal matrix formed by the squares roots of $\Omega_{11}, \ldots, \Omega_{\text {cld }}$, all variables $\omega^{-1}\left(Y_{i}-\xi_{i}\right)$ have distribution $\mathrm{ST}{d}(0, \bar{\Omega}, \alpha, v)$, for $i=1, \ldots, n$. Denote by $Z=\left(Z{1}, \ldots, Z_{d}\right)^{\top}$ the generic member of this set of variables. We are concerned with the distribution of the products $Z_{j} Z_{k}$, but for notational simplicity we focus on the specific product $W=Z_{1} Z_{2}$, since all other products are of similar nature.
We must then examine the distribution of $W=Z_{1} Z_{2}$ when $\left(Z_{1}, Z_{2}\right)$ is a bivariate ST variable. This looks at first to be a daunting task, but a major simplification is provided by consideration of the perturbation invariance property of symmetrymodulated distributions, of which the ST is an instance. For a precise exposition of this property, see for instance Proposition $1.4$ of Azzalini and Capitanio (2014), but in the present case it says that, since $W$ is an even function of $\left(Z_{1}, Z_{2}\right)$, its distribution does not depend on $\alpha$, and it coincides with the distribution of the case $\alpha=0$, that is, the case of a usual bivariate Student’s $t$ distribution, with dependence parameter $\bar{\Omega}_{12}$.
统计代写|生物统计代写biostatistics代考|Simulation Work to Compare Initialization Procedures
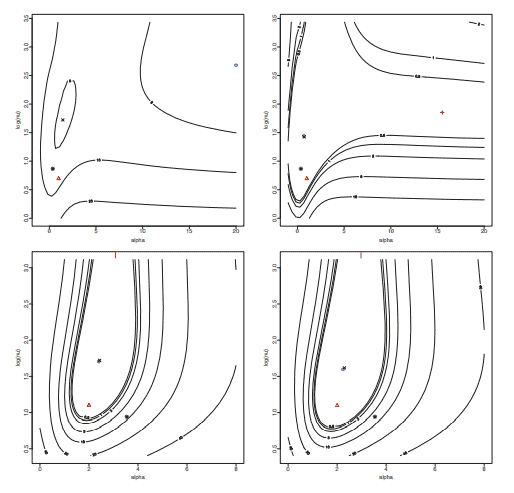
Several simulations runs have been performed to examine the performance of the proposed methodology. The computing environment was $\mathrm{R}$ version 3.6.0. The reference point for these evaluations is the methodology currently in use, as provided by the publicly available version of $R$ package $s n$ at the time of writing, namely version 1.5-4; see Azzalini (2019). This will be denoted ‘the current method’ in the following. Since the role of the proposed method is to initialize the numerical MLE search, not the initialization procedure per se, we compare the new and the current method with respect to final MLE outcome. However, since the numerical optimization method used after initialization is the same, any variations in the results originate from the different initialization procedures.
We stress again that in a vast number of cases the working of the current method is satisfactory and we are aiming at improvements when dealing with ‘awkward samples’. These commonly arise with ST distributions having low degrees of freedom, about $v=1$ or even less, but exceptions exist, such as the second sample in Fig. $2 .$
The primary aspect of interest is improvement in the quality of data fitting. This is typically expressed as an increase of the maximal achieved log-likelihood, in its penalized form. Another desirable effect is improvement in computing time.
The basic set-up for such numerical experiments is represented by simple random samples, obtained as independent and identically distributed values drawn from a named ST $(\xi, \omega, \lambda, v)$. In all cases we set $\xi=0$ and $\omega=1$. For the other ingredients, we have selected the following values:
$\lambda: 0, \quad 2, \quad 8$,
$v: 1,3,8$,
$n: 50,100,250,500$
and, for each combination of these values, $N=2000$ samples have been drawn.
The smallest examined sample size, $n=50$, must be regarded as a sort of ‘sensible lower bound’ for realistic fitting of flexible distributions such as the ST. In this respect, recall the cautionary note of Azzalini and Capitanio (2014, p. 63) about the fitting of a SN distribution with small sample sizes. Since the ST involves an additional parameter, notably one having a strong effect on tail behaviour, that annotation holds a fortiori here.
For each of the $3 \times 3 \times 4 \times 2000=72,000$ samples so generated, estimation of the parameters $(\xi, \omega, \lambda, \nu)$ has been carried out using the following methods.
生物统计代考
统计代写|生物统计代写biostatistics代考|Extension to the Regression Case
我们想扩展 Sect 的方法论。3.2回归设置,其中位置参数随观测值变化,作为一组线性函数p,比如说,假设包括常数项的解释变量,因为它通常是这种情况。如果X一世是与一世主题,观察是一世现在假设从 ST 中提取(X一世,ω,λ,ν)在哪里
X一世=X一世⊤b,一世=1,…,n,
对于一些p维向量b未知参数;因此现在参数向量是θ=(b⊤,ω,λ,在)⊤. 保留独立绘制观察的假设。
中值的直接扩展作为位置的估计,在 Sect. 3.2,是一个估计b通过中值回归获得,这对应于采用最小绝对偏差拟合标准而不是更熟悉的最小二乘法。当分位数水平设置为1/2. 分位数回归的经典处理
是 Koenker (2005),相应的数值工作可以使用Rquantreg 包,请参阅 Koenker (2018) 等工具。
使用中值回归提供估计b~~米的b和一个残差向量,r一世=是一世−X一世⊤b~米为了一世=1,…,n. 忽略b估计误差,这些残差是从小号吨(−米0,ω2,λ,在), 在哪里米0是一个合适的值,很快就会检查,这使得分布的中位数为 0,因为这是中位数回归标准的目标。然后我们可以使用 Sect 的相同程序。3.2,与是一世取代了r一世的,估计ω,λ,在,给定的值米0在这个阶段是无关紧要的。
最后一步是对向量的修正b~米调整的事实是一世−X一世⊤b应该有中位数米0,即 ST 的中位数(0,ω,λ,在),而不是中位数 0 。这相当于将所有残差增加一个恒定值米0, 这一步是通过设置一个向量来完成的b~所有组件都等于 tōb~米除了截距项,b0说,估计是
b~0=b~0米−ω~q2小号吨
类似于(10)
统计代写|生物统计代写biostatistics代考|Extension to the Multivariate Case
现在考虑以下情况n来自多变量的独立观察是随密度 (6) 变化,因此是∼小号吨d(X,Ω,一个,在). 这种情况可以结合Sect的回归设置。3.3,因此d- 维位置参数根据每个观察值变化
X一世⊤=X一世⊤b,一世=1,…,n,
现在在哪里b=(b⋅1,…,b⋅d)是一个p×d参数矩阵。由于我们假设解释变量包括一个常数项,回归情况包含相同分布的情况,当p=1. 因此,我们直接处理回归情况,其中一世第一次观察是从是一世∼ 小号吨d(X一世,Ω,一个,在)和X一世由 (12) 给出,对于一世=1,…,n.
将观测值排列在一个n×d矩阵是=(是一世j). 应用程序中介绍的部分。3.2和3.3分别到每一列是提供估计d单变量模型。具体来说,从j第 列是, 我们得到估计θ~j和相应的“归一化”残差和~一世j :
θ~j=(b~⋅j⊤,ω~j,λ~j,在~j)⊤,和~一世j=ω~j−1(是一世j−X一世⊤b~⋅j)
必须记住,“归一化”操作使用位置和尺度参数,但这些参数与基础随机变量的均值和标准差不一致。
由于表达式 (12) 的含义是定义一组具有共同设计矩阵的单变量回归模式,因此向量b~−1,…,b~⋅d可以简单地排列成一个p×d矩阵b~这代表了一个估计b.
(13)中的一组单变量估计提供d估计为在,而只有一个这样的值进入多元 ST 分布的规范。我们采用了 $\tilde{v} {1}、\ldots、\tilde{v} {d}的中位数一个s吨H和s一世nGl和r和q在一世r和d和s吨一世米一个吨和,d和n○吨和d\波浪号 {v} $。
规模数量ω~1,…,ω~d估计对角线元素的平方根Ω,但非对角线元素需要单独的估计步骤。真正需要估计的是无标度矩阵Ω¯. 这是接下来要研究的问题。
如果ω是由的平方根形成的对角矩阵Ω11,…,Ω分类 , 所有变量ω−1(是一世−X一世)有分布小号吨d(0,Ω¯,一个,在), 为了一世=1,…,n. 表示为从=(从1,…,从d)⊤这组变量的通用成员。我们关心产品的分销从j从ķ,但为了符号的简单性,我们专注于特定的产品在=从1从2,因为所有其他产品都具有相似的性质。
然后我们必须检查分布在=从1从2什么时候(从1,从2)是一个二元 ST 变量。起初这看起来是一项艰巨的任务,但考虑到对称调制分布的扰动不变性特性,提供了一个主要的简化,ST 就是其中的一个例子。有关此属性的精确说明,请参见例如 Proposition1.4Azzalini 和 Capitanio (2014),但在目前的情况下,它说,因为在是一个偶函数(从1,从2), 它的分布不依赖于一个,并且与案例的分布相吻合一个=0,即通常的双变量学生的情况吨分布,具有依赖参数Ω¯12.
统计代写|生物统计代写biostatistics代考|Simulation Work to Compare Initialization Procedures
已经进行了几次模拟运行以检查所提出的方法的性能。计算环境是R版本 3.6.0。这些评估的参考点是当前使用的方法,由公开版本提供R包裹sn在撰写本文时,即版本 1.5-4;见阿扎里尼 (2019)。这将在下文中表示为“当前方法”。由于所提出方法的作用是初始化数值 MLE 搜索,而不是初始化过程本身,我们比较新方法和当前方法的最终 MLE 结果。但是,由于初始化后使用的数值优化方法是相同的,因此结果的任何变化都源于不同的初始化程序。
我们再次强调,在大量情况下,当前方法的工作是令人满意的,我们的目标是在处理“尴尬样本”时进行改进。这些通常出现在具有低自由度的 ST 分布中,大约在=1甚至更少,但也有例外,例如图 2 中的第二个示例。2.
感兴趣的主要方面是数据拟合质量的改进。这通常以惩罚形式表示为最大实现对数似然的增加。另一个理想的效果是计算时间的改进。
此类数值实验的基本设置由简单的随机样本表示,这些样本是从命名的 ST 中提取的独立且同分布的值(X,ω,λ,在). 在所有情况下,我们设置X=0和ω=1. 对于其他成分,我们选择了以下值:
λ:0,2,8,
在:1,3,8,
n:50,100,250,500
并且,对于这些值的每种组合,ñ=2000样本已抽取。
最小的检查样本量,n=50, 必须被视为一种“合理的下界”,用于实际拟合灵活分布(例如 ST)。在这方面,回想一下 Azzalini 和 Capitanio (2014, p. 63) 关于在小样本量下拟合 SN 分布的警告说明。由于 ST 涉及一个附加参数,尤其是对尾部行为有强烈影响的参数,因此该注释在这里更重要。
对于每一个3×3×4×2000=72,000这样生成的样本,参数的估计(X,ω,λ,ν)已使用以下方法进行。

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。