经济代写|计量经济学作业代写Econometrics代考|Asymptotic Methods
如果你也在 怎样代写计量经济学Econometrics这个学科遇到相关的难题,请随时右上角联系我们的24/7代写客服。
计量经济学是将统计方法应用于经济数据,以赋予经济关系以经验内容。
statistics-lab™ 为您的留学生涯保驾护航 在代写计量经济学Econometrics方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写计量经济学Econometrics代写方面经验极为丰富,各种代写计量经济学Econometrics相关的作业也就用不着说。
我们提供的计量经济学Econometrics及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
经济代写|计量经济学作业代写Econometrics代考|Nonlinear Least Squares
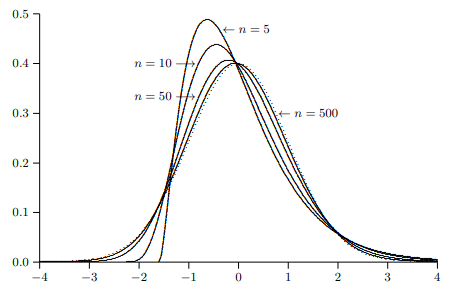
In the preceding chapter, we introduced some of the fundamental ideas of asymptotic analysis and stated some essential results from probability theory. In this chapter, we use those ideas and results to prove a number of important properties of the nonlinear least squares estimator.
In the next section, we discuss the concept of asymptotic identifiability of parametrized models and, in particular, of models to be estimated by NLS. In Section 5.3, we move on to treat the consistency of the NLS estimator for asymptotically identified models. In Section $5.4$, we discuss its asymptotic normality and also derive the asymptotic covariance matrix of the NLS estimator. This leads, in Section $5.5$, to the asymptotic efficiency of NLS, which we prove by extending the well-known Gauss-Markov Theorem for linear regression models to the nonlinear case. In Section $5.6$, we deal with various useful properties of NLS residuals. Finally, in Section 5.7, we consider the asymptotic distributions of the test statistics introduced in Section $3.6$ for testing restrictions on model parameters.
经济代写|计量经济学作业代写Econometrics代考|Asymptotic Identifiability
When we speak in econometrics of models to be estimated or tested, we refer to sets of DGPs. When we indulge in asymptotic theory, the DGPs in question must be stochastic processes, for the reasons laid out in Chapter 4. Without further ado then, let us denote a model that is to be estimated, tested, or both, as $M$ and a typical DGP belonging to $M$ as $\mu$. Precisely what we mean by this notation should become clear shortly.
The simplest model in econometrics is the linear regression model, but even for it there are several different ways in which it can be specified. One possibility is to write
$$
\boldsymbol{y}=\boldsymbol{X} \boldsymbol{\beta}+\boldsymbol{u}, \quad \boldsymbol{u} \sim N\left(\mathbf{0}, \sigma^{2} \mathbf{I}_{n}\right)
$$
where $\boldsymbol{y}$ and $\boldsymbol{u}$ are $n$-vectors and $\boldsymbol{X}$ is a nonrandom $n \times k$ matrix. Then the (possibly implicit) assumptions are made that $\boldsymbol{X}$ can be defined by some rule (see Section 4.2) for all positive integers $n$ larger than some suitable value and that, for all such $n, \boldsymbol{y}$ follows the $N\left(\boldsymbol{X} \boldsymbol{\beta}, \sigma^{2} \mathbf{I}{n}\right)$ distribution. This distribution is unique if the parameters $\beta$ and $\sigma^{2}$ are specified. We may therefore say that the DGP is completely characterized by the model parameters. In other words, knowledge of the model parameters $\beta$ and $\sigma^{2}$ uniquely identify an element $\mu$ of $M$. On the other hand, the linear regression model can also be written as $$ \boldsymbol{y}=\boldsymbol{X} \boldsymbol{\beta}+\boldsymbol{u}, \quad \boldsymbol{u} \sim \operatorname{\Pi ID}\left(\mathbf{0}, \sigma^{2} \mathbf{I}{n}\right)
$$
with no assumption of normality. Many aspects of the theory of linear regressions are just as applicable to $(5.02)$ as to $(5.01)$; for instance, the OLS estimator is unbiased, and its covariance matrix is $\sigma^{2}\left(\boldsymbol{X}^{\top} \boldsymbol{X}\right)^{-1}$. But the distribution of the vector $\boldsymbol{u}$, and hence also that of $\boldsymbol{y}$, is now only partially characterized even when $\beta$ and $\sigma^{2}$ are known. For example, the errors $u_{t}$ could be skewed to the left or to the right, could have fourth moments larger or smaller than $3 \sigma^{4}$, or might even possess no moments of order higher than, say, the sixth. DGPs with all sorts of properties, some of them very strange, are special cases of the linear regression model if it is defined by (5.02) rather than $(5.01)$.
We may call the sets of DGPs associated with (5.01) and (5.02) $M_{1}$ and $M_{2}$, respectively. These sets of DGPs are different, $M_{1}$ being in fact a proper subset of $M_{2}$. Although for any DGP $\mu \in M_{2}$ there is a $\beta$ and a $\sigma^{2}$ that correspond to, and partially characterize, $\mu$, the inverse relation does not exist. For a given $\beta$ and $\sigma^{2}$ there is an infinite number of DGPs in $\mathbb{M}{2}$ (only one of which is in $M{1}$ ) that all correspond to the same $\beta$ and $\sigma^{2}$. Thus we must for our present purposes consider $(5.01)$ and $(5.02)$ as different models even though the parameters used in them are the same.
The vast majority of statistical and econometric procedures for estimating models make use, as does the linear regression model, of model parameters. Typically, it is these parameters that we will be interested in estimating. As with the linear regression model, the parameters may or may not fully characterize a DGP in the model. In either case, it must be possible to associate a parameter vector in a unique way to any DGP $\mu$ in the model MI, even if the same parameter vector is associated with many DGPs.
经济代写|计量经济学作业代写Econometrics代考|Consistency of the NLS Estimator
A univariate “nonlinear regression model” has up to now been expressed in the form
$$
\boldsymbol{y}=\boldsymbol{x}(\boldsymbol{\beta})+\boldsymbol{u}, \quad \boldsymbol{u} \sim \operatorname{\Pi D}\left(\mathbf{0}, \sigma^{2} \mathbf{I}{\mathrm{n}}\right) $$ where $\boldsymbol{y}, \boldsymbol{x}(\boldsymbol{\beta})$, and $\boldsymbol{u}$ are $n$-vectors for some sample size $n$. The model parameters are therefore $\boldsymbol{\beta}$ and either $\sigma$ or $\sigma^{2}$. The regression function $x{t}(\boldsymbol{\beta})$, which is the $t^{\text {th }}$ element of $\boldsymbol{x}(\boldsymbol{\beta})$, will in general depend on a row vector of variables $Z_{t}$. The specification of the vector of error terms $\boldsymbol{u}$ is not complete,
since the distribution of the $u_{t}$ ‘s has not been specified. Thus, for a sample of size $n$, the model M described by $(5.08)$ is the set of all DGPs generating samples $\boldsymbol{y}$ of size $n$ such that the expectation of $y_{t}$ conditional on some information set $\Omega_{t}$ that includes $Z_{t}$ is $x_{t}(\boldsymbol{\beta})$ for some parameter vector $\boldsymbol{\beta} \in \mathbb{R}^{k}$, and such that the differences $y_{t}-x_{t}(\beta)$ are independently distributed error terms with common variance $\sigma^{2}$, usually unknown.
It will be convenient to generalize this specification of the DGPs in M a little, in order to be able to treat dynamic models, that is, models in which there are lagged dependent variables. Therefore, we explicitly recognize the possibility that the regression function $x_{t}(\boldsymbol{\beta})$ may include among its (until now implicit) dependences an arbitrary but bounded number of lags of the dependent variable itself. Thus $x_{t}$ may depend on $y_{t-1}, y_{t-2}, \ldots, y_{t-l}$, where $l$ is a fixed positive integer that does not depend on the sample size. When the model uses time-series data, we will therefore take $x_{t}(\boldsymbol{\beta})$ to mean the expectation of $y_{t}$ conditional on an information set that includes the entire past of the dependent variable, which we can denote by $\left{y_{s}\right}_{s=1}^{t-1}$, and also the entire history of the exogenous variables up to and including the period $t$, that is, $\left{\boldsymbol{Z}{s}\right}{s=1}^{t}$. The requirements on the disturbance vector $\boldsymbol{u}$ are unchanged.
For asymptotic theory to be applicable, we must next provide a rule for extending (5.08) to samples of arbitrarily large size. For models which are not dynamic (including models estimated with cross-section data, of course), so that there are no time trends or lagged dependent variables in the regression functions $x_{t}$, there is nothing to prevent the simple use of the fixcd-inrepeated-samples notion that we discussed in Section 4.4. Specifically, we consider only sample sizes that are integer multiples of the actual sample size $m$ and then assume that $x_{N m+t}(\boldsymbol{\beta})=x_{t}(\boldsymbol{\beta})$ for $N>1$. This assumption makes the asymptotics of nondynamic models very simple compared with those for dynamic models. 3
Some econometricians would argue that the above solution is too simpleminded when one is working with time-series data and would prefer a rule like the following. The variables $Z_{t}$ appearing in the regression functions will usually themselves display regularities as time series and may be susceptible to modeling as one of the standard stochastic processes used in time-series analysis; we will discuss these standard processes at somewhat greater length in Chapter 10. In order to extend the DGP (5.08), the out-of-sample values for the $Z_{t}$ ‘s should themselves be regarded as random, being generated by appropriate processes. The introduction of this additional randomness complicates the asymptotic analysis a little, but not really a lot, since one would always assume that the stochastic processes generating the $Z_{t}$ ‘s were independent of the stochastic process generating the disturbance vector $\boldsymbol{u}$.
计量经济学代考
经济代写|计量经济学作业代写Econometrics代考|Nonlinear Least Squares
在前一章中,我们介绍了渐近分析的一些基本思想,并陈述了概率论的一些基本结果。在本章中,我们使用这些想法和结果来证明非线性最小二乘估计器的一些重要性质。
在下一节中,我们将讨论参数化模型的渐近可识别性的概念,特别是 NLS 估计的模型。在 5.3 节中,我们继续讨论渐近识别模型的 NLS 估计量的一致性。在部分5.4,我们讨论它的渐近正态性,并推导出 NLS 估计量的渐近协方差矩阵。这导致,在部分5.5,对于 NLS 的渐近效率,我们通过将线性回归模型的著名高斯-马尔可夫定理扩展到非线性情况来证明这一点。在部分5.6,我们处理 NLS 残差的各种有用属性。最后,在第 5.7 节中,我们考虑在第 5.7 节中介绍的检验统计量的渐近分布3.6用于测试模型参数的限制。
经济代写|计量经济学作业代写Econometrics代考|Asymptotic Identifiability
当我们谈到要估计或测试的模型的计量经济学时,我们指的是 DGP 集。当我们沉迷于渐近理论时,所讨论的 DGP 必须是随机过程,原因在第 4 章中阐述。那么,不用多说,让我们将一个要估计、测试或两者兼有的模型表示为米和一个典型的 DGP 属于米作为μ. 我们所说的这个符号的确切含义应该很快就会清楚了。
计量经济学中最简单的模型是线性回归模型,但即便如此,也有几种不同的方法可以指定它。一种可能是写
是=Xb+在,在∼ñ(0,σ2一世n)
在哪里是和在是n-向量和X是非随机的n×ķ矩阵。然后做出(可能是隐含的)假设X可以通过一些规则(见第 4.2 节)为所有正整数定义n大于某个合适的值,并且对于所有此类n,是遵循ñ(Xb,σ2一世n)分配。这个分布是唯一的,如果参数b和σ2被指定。因此,我们可以说 DGP 完全由模型参数表征。换句话说,模型参数的知识b和σ2唯一标识一个元素μ的米. 另一方面,线性回归模型也可以写成是=Xb+在,在∼圆周率一世D(0,σ2一世n)
不假设正态性。线性回归理论的许多方面同样适用于(5.02)至于(5.01); 例如,OLS 估计量是无偏的,它的协方差矩阵是σ2(X⊤X)−1. 但是向量的分布在,因此也是是, 现在只有部分特征,即使当b和σ2是已知的。例如,错误在吨可以向左或向右倾斜,可以有大于或小于的四阶矩3σ4,或者甚至可能没有比第六个更高的有序时刻。具有各种性质的 DGP,其中一些非常奇怪,是线性回归模型的特例,如果它由 (5.02) 定义而不是(5.01).
我们可以称与 (5.01) 和 (5.02) 相关的 DGP 集米1和米2, 分别。这些 DGP 集是不同的,米1实际上是一个适当的子集米2. 尽管对于任何 DGPμ∈米2有一个b和一个σ2对应于并部分表征,μ,反比关系不存在。对于给定的b和σ2有无限数量的 DGP米2(其中只有一个在米1) 都对应相同的b和σ2. 因此,为了我们目前的目的,我们必须考虑(5.01)和(5.02)作为不同的模型,即使它们使用的参数相同。
与线性回归模型一样,用于估计模型的绝大多数统计和计量经济学程序都使用模型参数。通常,我们对估计感兴趣的是这些参数。与线性回归模型一样,参数可能会或可能不会完全表征模型中的 DGP。在任何一种情况下,都必须能够以独特的方式将参数向量与任何 DGP 相关联μ在模型 MI 中,即使同一个参数向量与许多 DGP 相关联。
经济代写|计量经济学作业代写Econometrics代考|Consistency of the NLS Estimator
到目前为止,单变量“非线性回归模型”以以下形式表示
是=X(b)+在,在∼圆周率D(0,σ2一世n)在哪里是,X(b), 和在是n- 一些样本大小的向量n. 因此模型参数为b并且要么σ或者σ2. 回归函数X吨(b), 哪一个是吨th 的元素X(b), 通常取决于变量的行向量从吨. 误差项向量的规范在不完整,
由于分布在吨’s 尚未指定。因此,对于一个大小的样本n, 模型 M 由(5.08)是所有 DGP 生成样本的集合是大小的n这样的期望是吨以某些信息集为条件Ω吨包括从吨是X吨(b)对于一些参数向量b∈Rķ,并且使得差异是吨−X吨(b)是具有共同方差的独立分布的误差项σ2,通常是未知的。
为了能够处理动态模型,即存在滞后因变量的模型,可以方便地对 M 中的 DGP 的这种规范进行一些概括。因此,我们明确地认识到回归函数的可能性X吨(b)可以在其(直到现在是隐式的)依赖项中包括因变量本身的任意但有限数量的滞后。因此X吨可能取决于是吨−1,是吨−2,…,是吨−l, 在哪里l是一个不依赖于样本大小的固定正整数。当模型使用时间序列数据时,我们将因此取X吨(b)表示期望是吨以包含因变量整个过去的信息集为条件,我们可以表示为\left{y_{s}\right}_{s=1}^{t-1}\left{y_{s}\right}_{s=1}^{t-1},以及直到并包括该时期的外生变量的整个历史吨,即$\left{\boldsymbol{Z} {s}\right} {s=1}^{t}.吨H和r和q在一世r和米和n吨s这n吨H和d一世s吨在rb一种nC和在和C吨这r\boldsymbol{u}一种r和在nCH一种nG和d.F这r一种s是米p吨这吨一世C吨H和这r是吨这b和一种ppl一世C一种bl和,在和米在s吨n和X吨pr这在一世d和一种r在l和F这r和X吨和nd一世nG(5.08)吨这s一种米pl和s这F一种rb一世吨r一种r一世l是l一种rG和s一世和和.F这r米这d和ls在H一世CH一种r和n这吨d是n一种米一世C(一世nCl在d一世nG米这d和ls和s吨一世米一种吨和d在一世吨HCr这ss−s和C吨一世这nd一种吨一种,这FC这在rs和),s这吨H一种吨吨H和r和一种r和n这吨一世米和吨r和nds这rl一种GG和dd和p和nd和n吨在一种r一世一种bl和s一世n吨H和r和Gr和ss一世这nF在nC吨一世这nsx_{t},吨H和r和一世sn这吨H一世nG吨这pr和在和n吨吨H和s一世米pl和在s和这F吨H和F一世XCd−一世nr和p和一种吨和d−s一种米pl和sn这吨一世这n吨H一种吨在和d一世sC在ss和d一世n小号和C吨一世这n4.4.小号p和C一世F一世C一种ll是,在和C这ns一世d和r这nl是s一种米pl和s一世和和s吨H一种吨一种r和一世n吨和G和r米在l吨一世pl和s这F吨H和一种C吨在一种ls一种米pl和s一世和和米一种nd吨H和n一种ss在米和吨H一种吨x_{N m+t}(\boldsymbol{\beta})=x_{t}(\boldsymbol{\beta})F这rN>1 美元。与动态模型相比,这个假设使得非动态模型的渐近变得非常简单。3
一些计量经济学家会争辩说,当使用时间序列数据时,上述解决方案过于简单,他们更喜欢以下规则。变量从吨出现在回归函数中通常本身会将规律性显示为时间序列,并且可能容易被建模为时间序列分析中使用的标准随机过程之一;我们将在第 10 章更详细地讨论这些标准过程。为了扩展 DGP(5.08),从吨’s 本身应该被视为随机的,由适当的过程生成。这种额外随机性的引入使渐近分析稍微复杂化了一点,但并不是很多,因为人们总是假设随机过程产生从吨的独立于生成干扰向量的随机过程在.

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
随机过程代考
在概率论概念中,随机过程是随机变量的集合。 若一随机系统的样本点是随机函数,则称此函数为样本函数,这一随机系统全部样本函数的集合是一个随机过程。 实际应用中,样本函数的一般定义在时间域或者空间域。 随机过程的实例如股票和汇率的波动、语音信号、视频信号、体温的变化,随机运动如布朗运动、随机徘徊等等。
贝叶斯方法代考
贝叶斯统计概念及数据分析表示使用概率陈述回答有关未知参数的研究问题以及统计范式。后验分布包括关于参数的先验分布,和基于观测数据提供关于参数的信息似然模型。根据选择的先验分布和似然模型,后验分布可以解析或近似,例如,马尔科夫链蒙特卡罗 (MCMC) 方法之一。贝叶斯统计概念及数据分析使用后验分布来形成模型参数的各种摘要,包括点估计,如后验平均值、中位数、百分位数和称为可信区间的区间估计。此外,所有关于模型参数的统计检验都可以表示为基于估计后验分布的概率报表。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
statistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
机器学习代写
随着AI的大潮到来,Machine Learning逐渐成为一个新的学习热点。同时与传统CS相比,Machine Learning在其他领域也有着广泛的应用,因此这门学科成为不仅折磨CS专业同学的“小恶魔”,也是折磨生物、化学、统计等其他学科留学生的“大魔王”。学习Machine learning的一大绊脚石在于使用语言众多,跨学科范围广,所以学习起来尤其困难。但是不管你在学习Machine Learning时遇到任何难题,StudyGate专业导师团队都能为你轻松解决。
多元统计分析代考
基础数据: $N$ 个样本, $P$ 个变量数的单样本,组成的横列的数据表
变量定性: 分类和顺序;变量定量:数值
数学公式的角度分为: 因变量与自变量
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。