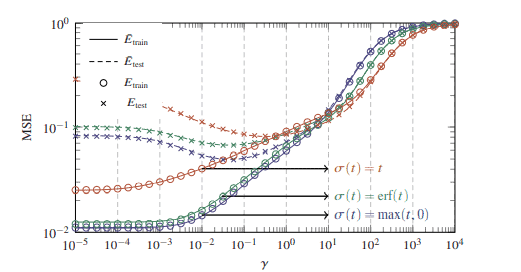
数学代写|运筹学作业代写operational research代考|MA3212
statistics-lab™ 为您的留学生涯保驾护航 在代写运筹学operational research方面已经树立了自己的口碑, 保证靠谱, 高质且原创的统计Statistics代写服务。我们的专家在代写运筹学operational research代写方面经验极为丰富,各种代写运筹学operational research相关的作业也就用不着说。
我们提供的运筹学operational research及其相关学科的代写,服务范围广, 其中包括但不限于:
- Statistical Inference 统计推断
- Statistical Computing 统计计算
- Advanced Probability Theory 高等楖率论
- Advanced Mathematical Statistics 高等数理统计学
- (Generalized) Linear Models 广义线性模型
- Statistical Machine Learning 统计机器学习
- Longitudinal Data Analysis 纵向数据分析
- Foundations of Data Science 数据科学基础
数学代写|运筹学作业代写operational research代考|Wertiteration
Nach Satz 9.1 lässt sich die Berechnung des maximalen Gesamtgewinns $V_0\left(s_0\right)$ und die Ermittlung einer optimalen Strategie $\delta^*$ auf das Lösen einer Funktionalgleichung, der Optimalitätsgleichung, zurückführen. Die effiziente Lösung der Optimalitätsgleichung im Hinblick auf die Rechenzeit und den Speicherbedarf gehört daher zu den zentralen Aufgaben der dynamischen Optimierung. Der Satz könnte rechentechnisch beispielsweise wie in Algorithmus $9.1$ umgesetzt werden.
Durch Rückwärtsrechnung berechnet man in Algorithmus $9.1$ zunächst die Wertfunktionen $V_{N-1}, \ldots, V_0$. Da $V_{N-1}, \ldots, V_1$ nur für jeweils einen Iterationsschritt benötigt werden und in die anschließende Vorwärtsrechnung nicht mehr eingehen, können sie überschrieben werden. Man benötigt somit nur eine neue Wertfunktion $v^{\prime}$ (Stufe $n$ ) und eine alte Wertfunktion $v$ (Stufe $n+1$ ), kommt also mit zwei Wertfunktionen aus.
Will man die Berechnung von Hand vornehmen, so ist es sinnvoll, dies in einer Tabellenform durchzuführen. Hierzu greifen wir noch einmal Beispiel $9.1$ auf. Insbesondere nehmen wir eine Reduktion auf das Basismodell der deterministischen dynamischen Optimierung vor und verifizieren die mit heuristischen Überlegungen bereits erzielte Lösung.
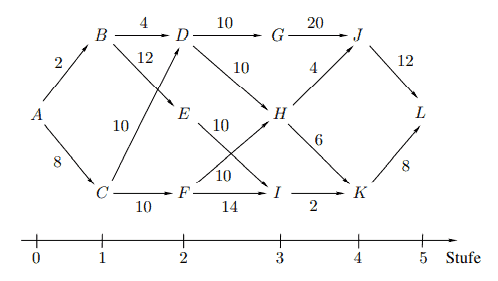
Bcispicl $9.4$ (Bcispicl $9.1$ – Fortsctzung 1).
Wir ordnen den Orten $A, B, \ldots, L$ die Zustände $1,2, \ldots, 12$ zu und wählen als Aktionen die Zustände der direkten Nachfolgeorte. Da unserem Basismodell ein Maximierungsproblem zugrunde liegt, fassen wir die einstufigen Gewinne als die negativen Entfernungen der benachbarten Orte auf. Ausgehend vom terminalen Gewinn $V_5\left(s_5\right)=V_5(12)=0$ empfiehlt es sich, für jede Stufe eine Tabelle anzulegen, in diese Tabelle für jeden Zustand in Abhängigkeit von den zulässigen Aktionen die Werte der rechten Seite der Optimalitätsgleichung aufzunehmen und die sich aus der Auswertung ergebende Wertfunktion sowie die zugehörigen Maximalpunkte zu notieren. Der letzten Tabelle kann man dann $V_0\left(s_0\right)$ unmittelbar entnehmen und eine optimale Strategie durch Vorwärtsrechnung aus den bereitgestellten Daten leicht ermitteln.
数学代写|运筹学作业代写operational research代考|Anwendungsbereiche
Die bisherigen Beispiele zeigen bereits, dass die dynamische Optimierung eine sehr flexible Lösungstechnik ist, die sich auf die unterschiedlichsten Problemstellungen anwenden lässt. Voraussetzung für eine Anwendung ist lediglich, dass sich das Problem in Teilprobleme zerlegen lässt mit einer stufenweisen Abarbeitungsmöglichkeit. Eine solche Zerlegung ist bei dynamischen Entscheidungsproblemen in natürlicher Weise gegeben und kann darüber hinaus auch bei statischen Entscheidungsproblemen als alternativer Lösungsansatz (vgl. Bsp. 9.2) gezielt eingesetzt werden.
Den Vorteilen einer einfachen Darstellung, die sich in der Regel auf die Aufstellung der Optimalitätsgleichung beschränkt, und einer einfachen Rechenvorschrift steht der Nachteil eines erhöhten Rechen- und Speicheraufwandes gegenüber, der aus der Bereithaltung einer Vielzahl von Informationen bei der Behandlung und Verknüpfung der Teilprobleme entsteht.
Zu den klassischen Anwendungen deterministischer dynamischer Optimierungsprobleme gehören die Berechnung kürzester Wege in einem Netzwerk (vgl. Bsp. 9.1), die Berechnung längster Wege im Rahmen der Zeitplanung innerhalb der Netzplantechnik (vgl. Kap. 4), die optimale Aufteilung von Ressourcen (als Verallgemeinerung von Reispiel 9.2) sowie die Insgrößenplanung im Rahmen der Materialhereitstellungsplanung, auf die wir in dem folgenden Beispiel $9.5$ eingehen werden.
Die Bedarfsmengen $x_0, \ldots, x_{N-1}$ eines Gutes seien über einen Planungszeitraum von $N$ Perioden bekannt und jeweils am Ende der Periode bereitzustellen. Fehlmengen seien nicht zulässig. In Periode $n, n=0, \ldots, N-1$, können $a_n$ Einheiten des Gutes hergestellt werden. Diese stehen am Ende der Periode zur Verfügung. Verbunden mit der Herstellung sind Kosten der Höhe $c\left(a_n\right)$. Nicht unmittelbar benötigte Einheiten des Gutes können gelagert werden. Die Lagerkosten $l\left(s_n\right)$ in der Periode $n$ ergeben sich aus dem Lagerbestand $s_n$ zu Beginn der Periode. Zu Beginn der ersten Periode sei der Lagerbestand Null, ebenso am Ende der letzten Periode (d.h. $\left.s_0=s_N=0\right)$.
运筹学代考
数学代写|运筹学作业代写operational research代考|Wertiteration
根据定理 9.1,可以计算出最大总利润 $V_0\left(s_0\right)$ 以及最优策略的确定 $\delta^*$ 求解函数方程,最优方程。因此, 关于计算时间和内存要求的最优性方程的有效解是动态优化的中心任务之一。该定理可以是计算性的,例 如在算法中 $9.1$ 予以实施。
通过逆向计算,在算法中计算 $9.1$ 首先是价值函数 $V_{N-1}, \ldots, V_0$. 和 $V_{N-1}, \ldots, V_1$ 只需要一个迭代步 旧值函数 $v($ 步 $n+1)$ ,所以它有两个价值函数。
如果您想手动进行计算,在表格中进行计算是有意义的。为此,我们再举一个例子9.1在。特别是,我们 对确定性动态优化的基本模型进行了简化,并通过启发式考虑验证了已经实现的解决方案。
双柱式 9.4(Bcispicl9.1- 续 1).
我们安排地点 $A, B, \ldots, L$ 条件 $1,2, \ldots, 12$ 并选择直接后继位置的状态作为动作。由于我们的基本模型 基于最大化问题,我们将单级增益视为相邻位置的负距离。从终端利润开始 $V_5\left(s_5\right)=V_5(12)=0$ 建议 为每个阶段创建一个表,根据允许的操作,将每个状态的最优方程右侧的值包含在该表中,并注意评估产 生的价值函数和相关的最大点数。然后您可以使用最后一张表 $V_0\left(s_0\right)$ 通过根据提供的数据进行正向计 算,立即轻松地确定最佳策略。
数学代写|运筹学作业代写operational research代考|Anwendungsbereiche
前面的示例已经表明,动态优化是一种非常灵活的解决方案技术,可以应用于各种问题。对应用程序的唯 一要求是问题可以分解为具有逐步处理选项的子问题。这种分解在动态决策问题中以自然的方式给出,也 可以作为替代方法以有针对性的方式用于静态决策问题(参见示例 9.2)。
简单表示 (通常仅限于最优方程的建立) 和简单计算规则的优点被计算和存储成本增加的缺点所抵消,这 些缺点是在处理和处理时提供大量信息而引起的。连接子问题。
确定性动态优化问题的经典应用包括网络中最短路径的计算 (参见示例 9.1) 、网络规划技术中时间规划 框架内最长路径的计算 (参见第 4 章) 、最优资源分配(作为示例 $9.2$ 的概括) 以及在材料可用性规划框 架内规划总体规模,我们在以下示例中引用 $9.5$ 将进入。
所需数量 $x_0, \ldots, x_{N-1}$ 的商品超过了规划期 $N$ 已知的时期并将在每个时期结束时提供。不允许缺少数 量。在期间 $n, n=0, \ldots, N-1$ , 能够 $a_n$ 单位的商品被生产出来。这些在期末可用。与生产相关的是 高度的成本 $c\left(a_n\right)$. 可以存储不是立即需要的商品单元。存储成本 $l\left(s_n\right)$ 在期间 $n$ 清单的结果 $s_n$ 在期初。 在第一期开始时,库存为零,与上一期末的情况一样 (即 $\left.s_0=s_N=0\right)$.

统计代写请认准statistics-lab™. statistics-lab™为您的留学生涯保驾护航。
金融工程代写
金融工程是使用数学技术来解决金融问题。金融工程使用计算机科学、统计学、经济学和应用数学领域的工具和知识来解决当前的金融问题,以及设计新的和创新的金融产品。
非参数统计代写
非参数统计指的是一种统计方法,其中不假设数据来自于由少数参数决定的规定模型;这种模型的例子包括正态分布模型和线性回归模型。
广义线性模型代考
广义线性模型(GLM)归属统计学领域,是一种应用灵活的线性回归模型。该模型允许因变量的偏差分布有除了正态分布之外的其它分布。
术语 广义线性模型(GLM)通常是指给定连续和/或分类预测因素的连续响应变量的常规线性回归模型。它包括多元线性回归,以及方差分析和方差分析(仅含固定效应)。
有限元方法代写
有限元方法(FEM)是一种流行的方法,用于数值解决工程和数学建模中出现的微分方程。典型的问题领域包括结构分析、传热、流体流动、质量运输和电磁势等传统领域。
有限元是一种通用的数值方法,用于解决两个或三个空间变量的偏微分方程(即一些边界值问题)。为了解决一个问题,有限元将一个大系统细分为更小、更简单的部分,称为有限元。这是通过在空间维度上的特定空间离散化来实现的,它是通过构建对象的网格来实现的:用于求解的数值域,它有有限数量的点。边界值问题的有限元方法表述最终导致一个代数方程组。该方法在域上对未知函数进行逼近。[1] 然后将模拟这些有限元的简单方程组合成一个更大的方程系统,以模拟整个问题。然后,有限元通过变化微积分使相关的误差函数最小化来逼近一个解决方案。
tatistics-lab作为专业的留学生服务机构,多年来已为美国、英国、加拿大、澳洲等留学热门地的学生提供专业的学术服务,包括但不限于Essay代写,Assignment代写,Dissertation代写,Report代写,小组作业代写,Proposal代写,Paper代写,Presentation代写,计算机作业代写,论文修改和润色,网课代做,exam代考等等。写作范围涵盖高中,本科,研究生等海外留学全阶段,辐射金融,经济学,会计学,审计学,管理学等全球99%专业科目。写作团队既有专业英语母语作者,也有海外名校硕博留学生,每位写作老师都拥有过硬的语言能力,专业的学科背景和学术写作经验。我们承诺100%原创,100%专业,100%准时,100%满意。
随机分析代写
随机微积分是数学的一个分支,对随机过程进行操作。它允许为随机过程的积分定义一个关于随机过程的一致的积分理论。这个领域是由日本数学家伊藤清在第二次世界大战期间创建并开始的。
时间序列分析代写
随机过程,是依赖于参数的一组随机变量的全体,参数通常是时间。 随机变量是随机现象的数量表现,其时间序列是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。研究时间序列数据的意义在于现实中,往往需要研究某个事物其随时间发展变化的规律。这就需要通过研究该事物过去发展的历史记录,以得到其自身发展的规律。
回归分析代写
多元回归分析渐进(Multiple Regression Analysis Asymptotics)属于计量经济学领域,主要是一种数学上的统计分析方法,可以分析复杂情况下各影响因素的数学关系,在自然科学、社会和经济学等多个领域内应用广泛。
MATLAB代写
MATLAB 是一种用于技术计算的高性能语言。它将计算、可视化和编程集成在一个易于使用的环境中,其中问题和解决方案以熟悉的数学符号表示。典型用途包括:数学和计算算法开发建模、仿真和原型制作数据分析、探索和可视化科学和工程图形应用程序开发,包括图形用户界面构建MATLAB 是一个交互式系统,其基本数据元素是一个不需要维度的数组。这使您可以解决许多技术计算问题,尤其是那些具有矩阵和向量公式的问题,而只需用 C 或 Fortran 等标量非交互式语言编写程序所需的时间的一小部分。MATLAB 名称代表矩阵实验室。MATLAB 最初的编写目的是提供对由 LINPACK 和 EISPACK 项目开发的矩阵软件的轻松访问,这两个项目共同代表了矩阵计算软件的最新技术。MATLAB 经过多年的发展,得到了许多用户的投入。在大学环境中,它是数学、工程和科学入门和高级课程的标准教学工具。在工业领域,MATLAB 是高效研究、开发和分析的首选工具。MATLAB 具有一系列称为工具箱的特定于应用程序的解决方案。对于大多数 MATLAB 用户来说非常重要,工具箱允许您学习和应用专业技术。工具箱是 MATLAB 函数(M 文件)的综合集合,可扩展 MATLAB 环境以解决特定类别的问题。可用工具箱的领域包括信号处理、控制系统、神经网络、模糊逻辑、小波、仿真等。